
High-performance computing (HPC) cluster architecture [part 4]
by Jon Thor Kristinsson on 12 July 2022
In this blog, we will give an insightful overview of HPC clusters, their architecture, components and structure.
This blog is part of a series of blogs where we will introduce you to the world of HPC.
- What is High-performance computing? – Introduction to the concept of HPC
- High-performance computing clusters anywhere – Introduction to HPC cluster hosting
- What is supercomputing? A short history of HPC and how it all started with supercomputers
- Open source in HPC – An overview of how open source has influenced and driven HPC
- High-performance computing (HPC) technologies – what does the future hold?
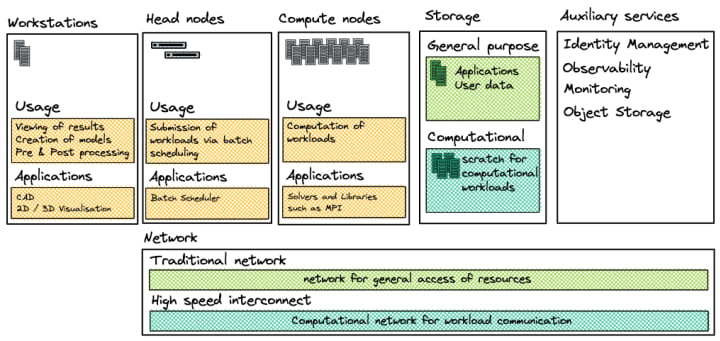
What are HPC clusters?
HPC clusters are a collection of resources used for the primary purpose of running computational workloads.
HPC clusters consist of:
- A cluster provisioner that ensures node homogeneity.
- Servers, often referred to as nodes.
- A scheduler that queues up workloads against the cluster resources.
- A network for communication between nodes.
- A general-purpose storage solution used to store applications and user data.
- A high-speed, low-latency clustered file system generally used for computational storage.
- Workstations that interact with the workload, either pre or post computation.
- Identity management to keep user access consistent throughout a cluster.
- An observability & monitoring stack that provides insight into workload resource utilisation.
- Object Storage, in some cases.
This post will explore each of these resources in more detail. Before we delve in, let’s look at the defining characteristics of HPC workloads.
HPC Workloads
While you can run HPC workloads on a single server or node, the real potential of high performance computing comes from running computationally intensive tasks as processes across multiple nodes. These different processes work together in parallel as a single application. To ensure communication between processes across nodes, you need a messaging passing mechanism. The most common implementation of this in HPC is known as MPI (Message Passing Interface).
What is MPI (Message Passing Interface)?
MPI is a communication protocol and a standard used to enable portable message passing from the memory of one system to another on parallel computers. Thanks to message-passing, computational workloads can be run across compute nodes that are connected via a high speed networking link. This was vital to the development of HPC, as it allowed an ever greater number of organisations to solve their computational problems at a lower cost and at a greater scale than ever before. Suddenly, they were no longer limited to the computational ability of a single system.
MPI libraries provide abstractions that enable point-to-point and collective communication between processes. They are available for most programming languages and are used by most parallel workloads to reach unparalleled scale across large clusters.
Implementations of MPI Solutions in this space include:
Cluster provisioning
Besides message passing, node homogeneity is very important in HPC to ensure workload consistency. That’s why it’s common to see HPC clusters provisioned with metal as a service solutions that help organisations manage this infrastructure at scale.
Implementations of cluster provisioning solutions include:
Head nodes
Head nodes or access nodes act as an entry point into an HPC cluster. It’s where users interact with the input and output of their workloads and get access to the local storage systems available to that cluster. It’s also where they schedule their workloads. The scheduler, in turn, executes processes on compute nodes.
Schedulers
In HPC, a scheduler queues up workloads against the resources of the cluster in order to orchestrate its use. Schedulers act as the brain for the clusters. They receive any requests for workloads that need to be scheduled from users of the cluster, keep track of them and then run those workloads as needed when resources are available. Schedulers are aware of any resource availability and utilisation and do their best to consider any locality that might affect performance. Their main purpose is to schedule compute jobs based on optimal workload distribution. The schedule is often based on organisational needs.
The scheduler keeps track of the workloads and sends workloads over to another integral component: an application process that runs on the compute nodes to execute that workload.
Solutions in this space include:
- SLURM by SchedMD
- OpenPBS and Altair PBS Professional
- Altair Grid Engine
- Moab HPC Suit from Adaptive Computing
Compute nodes
Compute notes are the processing component of an HPC cluster. They execute the workload using local resources, like CPU, GPU, FPGA and other processing units. These workloads also use other resources on the compute node for processing, such as the memory, storage and network adapter. The workloads use the available bandwidth of these underlying components. Depending on how the workload uses those components, it can be limited by one or more of those during execution. For example, some workloads that use a lot of memory might be limited on memory bandwidth or capacity. Workloads that either use a lot of data or generate a large amount of data during computation might be limited in their processing speed due to network bandwidth or storage performance constraints – if that data is written down to storage as part of the computation of that workload. Some workloads might just need plenty of computational resources and be limited by the processing ability of the cluster.
When creating and designing these clusters, it’s important to understand the resource utilisation of the workload and design the cluster with that in mind. The best way to understand workload resource usage is by monitoring the resources used. This allows you to gain an understanding of the limitations.
Networks
As we mention above, parallel HPC workloads are heavily dependent on inter-process communication. When that communication takes place within a compute node, it’s just passed from one process to another through the memory of that computational node. But when a process communicates with a process on another computational node, that communication needs to go through the network. This inter-process communication might be quite frequent. If that’s the case, it’s important that the network has low latency to prevent communication delays between processes. After all, you don’t want to spend valuable computation time on processes that are awaiting message deliveries. In cases where data sizes are large, it’s important to deliver that data as fast as possible. That’s enabled by high throughput networks. The faster the network can deliver data, the sooner any processes can start working on the workload. Frequent communication and large message and data sizes are regular features of HPC workloads. This has led to the creation of specialised networking solutions that often deliver low latency and high throughput to meet HPC-specific demands.
Solutions in this space include:
- Nvidia InfiniBand
- HPE Cray Slingshot
- Ethernet with or without RoCE
- Cornellis OmniPath
- Rockport switchless networks
Storage
Storage solutions in the HPC space are most commonly file-based, with POSIX support. These file-based solutions can be generally abstracted into two categories, general purpose and parallel storage solutions. Other solutions such as Object storage, or Blob (Binary Large Objects) storage, as it’s sometimes referred to in HPC, can be utilised by some workloads directly but not all workloads have that capability.
General-purpose storage
There are two main uses for general-purpose storage in a HPC cluster. One would be for the storage of available application binaries and their libraries. That’s because it’s important that all binaries and libraries are consistent across the cluster when running an application, making central storage convenient. The other would be for the user’s home directories and other user data, as it’s important for the user to have consistent access to their data throughout the HPC cluster. It’s common to use a NFS server for this purpose, but other storage protocols do exist that enable POSIX based file access.
Clustered file system
A clustered file system or parallel file system is a shared file system which serves storage resources from multiple servers and can be mounted and used by multiple clients at the same time. This gives clients direct access to stored data, which, in turn, cuts out overheads by avoiding abstraction, resulting in low latency and high performance. Some systems are even able to reach performance similar to total underlying hardware aggregate performance.
Solutions in this space include:
- Ceph via CephFS
- BeeGFS
- Lustre / DDN Lustre
- DAOS
- GPFS / IBM Spectrum Scale
- VAST Data
- WekaIO WekaFS
- Panasas PanNFS
Object storage solutions
Object storage solutions are often used for storage in HPC clusters, either to archive past computational results or other related data. Alternatively, they may be used directly by workloads that support native object storage APIs.
Solutions in this space include:
- Ceph Object Storage
- Swift
- Minio
Remote visualisation and workstations
Users should be able to define workloads and view their results before and after computation. This generally takes place on workstations. Those can either be local to the user or accessed remotely. It’s common for HPC workloads to have a pre and post processing step. This can sometimes be the creation of a CAD-based 3D model or a visual simulation, graphical data or numerical results. This is often accomplished with graphical VDI resources, co-located with the HPC cluster resources where there are data transfer considerations. Conversely, it can be implemented with local workstations where data is either transferred to or from the HPC cluster, as required for local viewing or further work.
Cluster management solutions for VDI with GPU or vGPU support include:
- OpenStack managing VDI resources
- MAAS and LXD managing VDI resources
- Solutions from Citrix
Components closely related to delivering remote workstation experience would include:
- Remote access software such as VNC provides access to the desktop environment.
- Desktop environment such as Ubuntu Desktop running on a VM.
Auxiliary Services
Many software components can be used to improve the usage of HPC clusters. These include anything from identity management to monitoring and observability software.
Identity management
Identity access managers are quite common in HPC clusters. They serve as the single source of truth for identity and access management. Unified access makes it easy for users to access any node in the cluster. This is often a prerequisite for resource scheduling. For example, if you want to run a parallel job across multiple nodes in the cluster via a batch scheduler, you need consistent access to compute nodes and storage resources. An identity management solution can help you ensure consistency. Without it, as an administrator, you would need to ensure both user creation, identity and storage configurations, all lined up across the cluster through individually configured nodes.
Solutions in this space include:
Monitoring and Observability
Monitoring and observability tools provide deeper insight into workload resource utilisation and are thus key to solving any performance issues or detecting issues with overall cluster health.
Solutions in this space include:
Summary
This article describes what HPC clusters are, their various components and their particular purposes. It also covers the different types of HPC clusters.
If you’re interested in more information take a look at the previous blog in the series “What is supercomputing?” You can also watch how Scania is Mastering multi cloud for HPC systems with Juju, or dive into some of our other HPC content.
In the next blog, we will cover the many ways open source has influenced the HPC industry and some of the common open source solutions in HPC.

Related posts
High-performance computing (HPC) technologies: what does the future hold? [part 6]
his is a very exciting time for HPC, as we are seeing a lot of innovation in the space. Servers are taking on advanced capabilities in terms of compute and networking and we are seeing compatibility increase. Overall cluster deployment and usage is being driven by ease of use. […]
Open Source in HPC [part 5]
Introduction to open source HPC focused applications and components. […]
Managing Ubuntu on bare metal at scale
Modern infrastructure teams are expected to deliver cloud-like speed, consistency, and reliability, even when their workloads run on physical servers. Bare metal remains essential for many environments: private clouds, Kubernetes clusters, AI infrastructure, edge sites, regulated platforms, and large Ubuntu estates. But operating physical […]