
Deploying Kubernetes at the edge – Part I: building blocks
by Carmine Rimi on 11 July 2019
Edge computing continues to gain momentum to help solve unique challenges across telco, media, transportation, logistics, agricultural and other market segments. If you are new to edge computing architectures, of which there are several, the following diagram is a simple abstraction for emerging architectures:
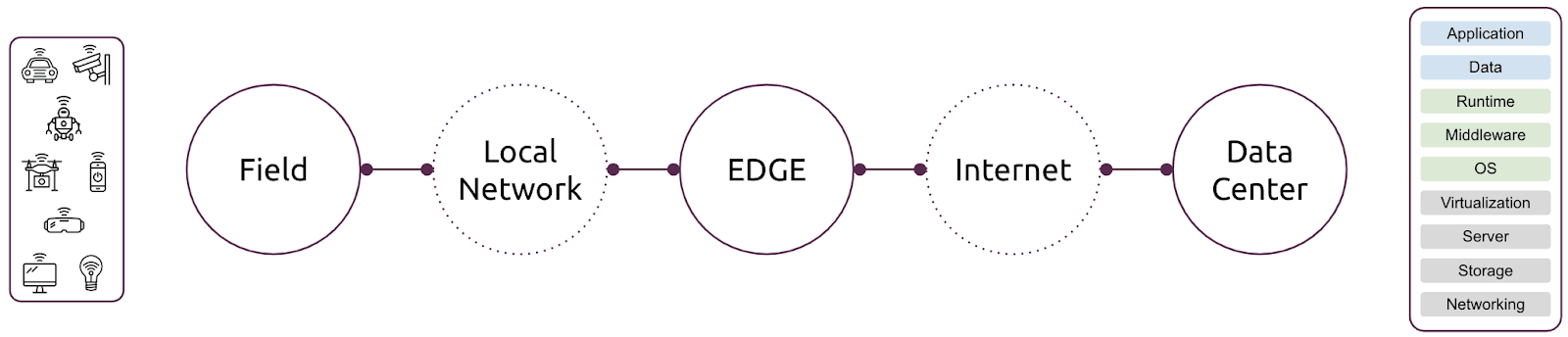
In this diagram you can see that an edge cloud sits next to field devices. In fact, there is a concept of extreme edge computing which puts computing resources in the field – which is the circle on the far left. An example of extreme edge computing is a gateway device that connects to all of your office or home appliances and sensors.
What exactly is edge computing? Edge computing is a variant of cloud computing, with your infrastructure services – compute, storage, and networking – placed physically closer to the field devices that generate data. Edge computing allows you to place applications and services closer to the source of the data, which gives you the dual benefit of lower latency and lower Internet traffic. Lower latency boosts the performance of field devices by enabling them to not only respond quicker, but to also respond to more events. And lowering Internet traffic helps reduce costs and increase overall throughput – your core datacenter can support more field devices. Whether an application or service lives in the edge cloud or the core datacenter will depend on the use case.
How can you create an edge cloud? Edge clouds should have at least two layers – both layers will maximise operational effectiveness and developer productivity – and each layer is constructed differently.
The first layer is the Infrastructure-as-a-Service (IaaS) layer. In addition to providing compute and storage resources, the IaaS layer should satisfy the network performance requirements of ultra-low latency and high bandwidth.
The second layer is the Kubernetes layer, which provides a common platform to run your applications and services. Whereas using Kubernetes for this layer is optional, it has proven to be an effective platform for those organisations leveraging edge computing today. You can deploy Kubernetes to field devices, edge clouds, core datacenters, and the public cloud. This multi-cloud deployment capability offers you complete flexibility to deploy your workloads anywhere you choose. Kubernetes offers your developers the ability to simplify their devops practices and minimise time spent integrating with heterogeneous operating environments.
Okay, but how can I deploy these layers? At Canonical, we accomplish this through the use of well defined, purpose-built technology primitives. Let’s start with the IaaS layer, which the Kubernetes layer relies upon.
Physical infrastructure lifecycle management
The first step is to think about the physical infrastructure, and what technology can be used to manage the infrastructure effectively, converting the raw hardware into an IaaS layer. Metal-as-a-Service (MAAS) has proven to be effective in this area. MAAS provides the operational primitives that can be used for hardware discovery, giving you the flexibility to allocate compute resources and repurpose them dynamically. These primitives expose bare metal servers to a higher level of orchestration through open APIs, much like you would experience with OpenStack and public clouds.

With the latest MAAS release you can automatically create edge clouds based on KVM pods, which effectively enable operators to create virtual machines with pre-defined sets of resources (RAM, CPU, storage and over-subscription ratios). You can do this through the CLI, Web UI or the MAAS API. You can use your own automation framework or use Juju, Canonical’s advanced orchestration solution.
MAAS can also be deployed in a very optimised fashion to run on top of the rack switches – just as we demonstrated during the OpenStack Summit in Berlin.

Image 1: OpenStack Summit Demo : MAAS running on ToR switch (Juniper QFX5100AA)
Edge application orchestration
Once discovery and provisioning of physical infrastructure for the edge cloud is complete, the second step is to choose an orchestration tool that will make it easy to install Kubernetes, or any software, on your edge infrastructure. Juju allows you to do just that – you can easily install Charmed Kubernetes, a fully compliant and upstream Kubernetes. And with Kubernetes you can install containerised workloads, offering them the highest possible performance. In the telecommunications sector, workloads like Container Network Functions (CNFs) are well suited to this architecture.
There are additional benefits to Charmed Kubernetes. With the ability to run in a virtualised environment or directly on bare metal, fully automated Charmed Kubernetes deployments are designed with built-in high availability, allowing for in place, zero downtime upgrades. This is a proven, truly resilient edge infrastructure architecture and solution. An additional benefit of Charmed Kubernetes is its ability to automatically detect and configure GPGPU resources for accelerated AI model inferencing and containerised transcoding workloads.
Next steps
Once the proper technology primitives are selected, it is time to deploy the environment and start onboarding and validating the application. The next part of this blog series will include hands-on examples of what to do.
Related posts
Managing Ubuntu on bare metal at scale
Modern infrastructure teams are expected to deliver cloud-like speed, consistency, and reliability, even when their workloads run on physical servers. Bare metal remains essential for many environments: private clouds, Kubernetes clusters, AI infrastructure, edge sites, regulated platforms, and large Ubuntu estates. But operating physical […]
Ubuntu Server: a platform made for enterprise scale
A platform is an environment that allows software to run smoothly across the infrastructure, runtime, and application layers. The key word there is “smoothly”: a good platform connects those layers so well that you don’t notice it. That’s what Ubuntu Server has become: the essential layer between bare metal and the apps running on top, […]
VMware hypervisor deployment using MAAS
Most modern datacenters are inherently heterogeneous. VMware environments coexist with container platforms, databases, and other bare-metal workloads, often on the same hardware over several years. Servers are bought once, but their role changes as requirements evolve. However, ESXi (the VMware hypervisor) provisioning is often handled se […]